반응형
◈ 출처: http://ari-ava.blogspot.com/2014/07/opw-linux-block-io-layer-part-4-multi.html
So, a couple of weeks ago I performed some first tests on the prototype driver using a simulated device created with the null_blk device driver. Such tests, and the following profiling, highlighted some locking issues due to contention on an internal lock kept by the frontend driver; more in detail, such a lock is instrumental to handling a ringbuffer which is used to exchange requests and responses between the frontend and the backend parts of the block I/O driver: the lock protects the ring against the insertion of new requests and the extraction of responses. My very patient OPW mentor has therefore suggested splitting the ring into two separate halves, one used for requests and another used for responses. During the last week and a half I have been working on that; while struggling with making the interface consistent with the needs of older versions of the driver, I have been writing this last blog article about the multi-queue block layer API, which concludes the series; next week I'll bore you to death with something more related to performance. Also, please note that this post is the reword of some documentation I produced during the first weeks of internship, and it has had the benefit of my mentor's reading, so it's probably much more accurate than usual.
The block I/O layer, part 4 - The multi-queue interface
The request interface was designed for devices that could handle hundreds of I/O operations per second; in a recent paper, block layer maintainer Jens Axboe noted that it suffers from design issues when used for devices that can handle hundreds of thousands of IOPS (see my first blog post or, much better, Jens Axboe's paper). One of the capital issues, lock contention, has very relevant effects event if only having multiple cores concurrently inserting block I/O requests and continuously spinning on the single queue_lock; such a situation is exacerbated when the lock is conteded also by a high-end storage device issuing interrupts and whose driver is still spinning on that same lock. The multi-queue API (also referred to as blk-mq) addresses such an issue by exploiting the ability of block I/O controllers to handle multiple requests in parallel, and thus dramatically reducing lock contention; in fact, in its most common configuration, it allows for block I/O requests to be inserted without the need to lock the whole request_queue. Let's see how it manages to do it.
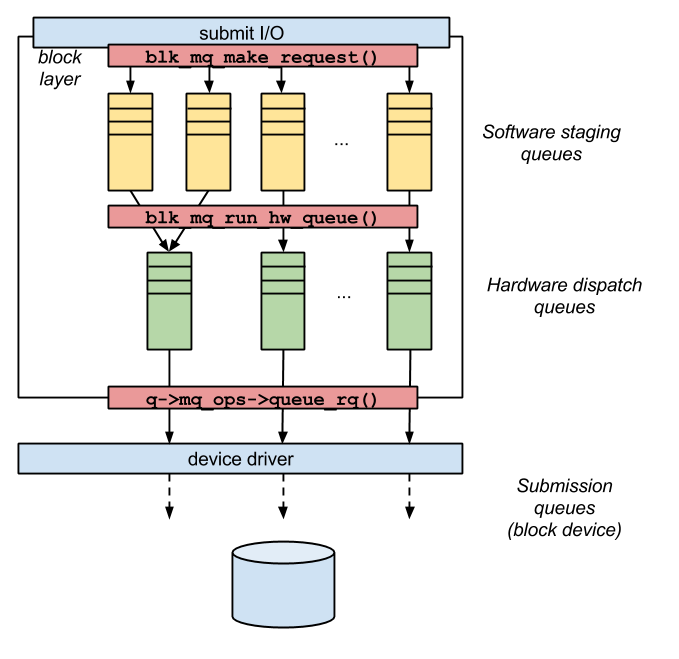
The blk-mq API implements a two-levels block layer design which makes use of two separate sets of request queues: software staging queues, allocated per-CPU, and hardware dispatch queues, whose number typically match the number of actual hardware queues supported by the block device. The number of software staging queues can be higher than the number of hardware dispatch queues: in this case, two or more software queues will be part of the same hardware context, and a dispatch performed with that hardware context will pull in requests from all the associated software queues. The number of software staging queues can be, instead, less than the number of hardware queues: in this case, sequential mapping is performed. In the third and most simple case where the number of software queues equals the number of hardware queues, a direct 1:1 mapping is performed.

Main data structures
The first relevant data structure used by the multi-queue block layer API is the blk_mq_reg structure, containing all informations of importance during the registration of a new block device to the block layer. This data structure contains the pointer to a blk_mq_ops data structure, used to keep track of the specific routines to be used by the multi-queue block layer to interact with the device's driver. A blk_mq_reg structure also keeps the number of hardware queues to be initialized, the dept of such queues and other information useful during the initialization of data structures related to the particular driver in the block layer. Another data structure of importance is the blk_mq_hw_ctx structure, which represents the hardware context to which a request_queue is associated. Its corresponding structure for the software staging queue is the blk_mq_ctx structure, which is allocated per-CPU. The function performing the mapping between these contexts is specified in the map_queue field of the driver's blk_mq_ops data structure, while the mapping built by this function is kept as the mq_map of the request_queue data structure associated to the block device.
Don't worry: a drawing, such as Figure 2, makes it clearer. Kind of.

Queue initialization
When a new device driver using the multi-queue API is loaded, it creates and initializes a new blk_mq_ops structure and sets to its address the related pointer of a new blk_mq_reg. More in detail, the required operations are queue_fn, which must be set to a function in charge of handling the command (e.g. by passing it to the low-level driver), and map_queue, which performs the mapping between hardware and software contexts. Other operations are not strictly required, but can be specified in order to perform specific operations on allocation of contexts or on completion of an I/O request. As of necessary data, the driver must initialize the number of submission queues it supports, along with their size; other data are required, e.g., to determine the size of the command supported by the driver and specific flags that must be exposed to the block layer.
When a new device is initialized, its driver prepares a new data structure whose type may vary according to the device driver handling the device; such a driver-specific data structure, however, is very likely to contain a pointer to the device's gendisk struct and to the request_queue related to the device. As soon as the driver has these data structures ready, it invokes the blk_mq_init_queue() function, which initializes the hardware and software contexts and performs the mapping between them. The initialization routine also sets an alternate make_request function, subsituting to the conventional request submission path (which would include blk_make_request()) the multi-queue submission path (which includes, instead, the function blk_mq_make_request()); as usual, the alternate make_request function is set with the blk_queue_make_request() helper.
Request submission
Device initialization substituted the conventional block I/O submission function with the multi-queue-ready request-submission function, blk_mq_make_request(), letting the multi-queue structures be used transparently from the perspective of the upper layers. The make_request function used by the multi-queue block layer includes the possibility to benefit from per-process plugging, but only for drivers supporting a single hardware queue or for async requests. In case the request is sync and the driver actively uses the multi-queue interface, no plugging is performed. The make_request function also performs request merging, searching for a candidate first inside the task's plug list, if plugging is allowed, and finally in the software queue mapped to the current CPU; the submission path does not involve any I/O scheduling-related callback. Finally, make_request sends immediately to the corresponding hardware queue any sync request, while it delays this transition in case of async or flush requests, to allow for subsequent merging and more efficient dispatching.
Request dispatch
In case that an I/O request is synchronous (and therefore no plugging is allowed for it from the multi-queue block layer) its dispatch to the device driver is performed in the context of the same request; if the request is instead async or flush, and task plugging is present, its dispatch can be performed: a) in the context of the submission of another I/O request to a software queue associated to the same hardware queue; b) when the delayed work scheduled during request submission is executed.
The main run-of-queue function of the multi-queue block layer is the blk_mq_run_hw_queue(), which basically relies on another driver-specific routine, pointed by the queue_rq field of its blk_mq_ops structure. This function delays any run of queue for an async request, while it dispatches a sync request immediately to the driver. The inner function __blk_mq_run_hw_queue(), called by blk_mq_run_queue() in case the request is sync, first joins any software queue associated to the currently-in-service hardware queue; then it joins the resulting list with any entry already on the dispatch list. After collecting all to-be-served entries, the function processes them, starting each request and passing it on to the driver, with its queue_rq function. The function finally handles possible errors, by requeue or deletion of the associated requests.
반응형
'【Fundamental Tech】 > Linux' 카테고리의 다른 글
| 깨진 심볼릭 링크 검색/삭제 (0) | 2023.05.07 |
|---|---|
| Linux Storage Stack Diagram (0) | 2022.11.20 |
| The block I/O layer, part 3 - The make request interface (0) | 2022.11.19 |
| The block I/O layer, part 2 - The request interface (0) | 2022.11.19 |
| The block I/O layer, part 1 - Base concepts (0) | 2022.11.19 |



