반응형
◈ 출처: http://ari-ava.blogspot.com/2014/06/opw-linux-block-io-layer-part-1-base.html
So, during the last few weeks I have been studying and tracing the block I/O layer of the Linux kernel, with the aim of getting a clearer view of how it works. A fellow student from the University of Modena and Reggio Emilia thought I might write a blog post on that. My very patient OPW mentor approved the topic and suggested that I split the blog post in different parts, so that it can be read more comfortably and without getting bored all at once. Here is part one, which attempts to explain the basic concepts and ideas behind the mechanisms implemented in the block I/O layer: it's very high-level and concise. The following parts (which will go into much more detail about implementation details) will outline how the different APIs that the block layer exposes make use of those mechanisms, and hopefully why they are useful (or they aren't) to each of the APIs. Sounds like a pretty difficult goal (at least for a beginner as I am), so if you have any criticism, please, go ahead and leave a comment.
The block I/O layer, part 1 - Base concepts
The block I/O layer is the kernel subsystem in charge of managing input/output operations performed on block devices. The need for a specific kernel component for managing such operations is given by the additional complexity of block devices with respect to, for example, character devices. When we think about a character device (e.g. the keyboard we're writing with), we think about a stream, which has a cursor running along one only direction. In other words, the information kept in the stream can be read in only one order, and is usually read until a certain position, or until a certain special character is encountered (e.g. EOF, the end-of-file character). A block device is different: data can be read from it in any order and from any position, after one or more seeks. Extra care is needed while reading from a block device, not so much for handling the I/O itself, as for ensuring performance; in fact, block I/O devices are mainly exploited as storage devices, and it is important to exploit as much as possible their potential. As Robert Love stated in his renowned book, the development of a block layer was such an important goal that it became the main aim of the 2.5 development cycle of the Linux kernel.
Seeing it as a black box, we find that the block layer interacts with two other relevant subsystems of the Linux kernel: the mapping layer and the device driver of the block device where the actual I/O will take place. To undestand what the mapping layer does, and how it interacts with the block layer, we have to briefly outline how a block I/O request actually reaches it (see also Figure 1 for a schematic view).
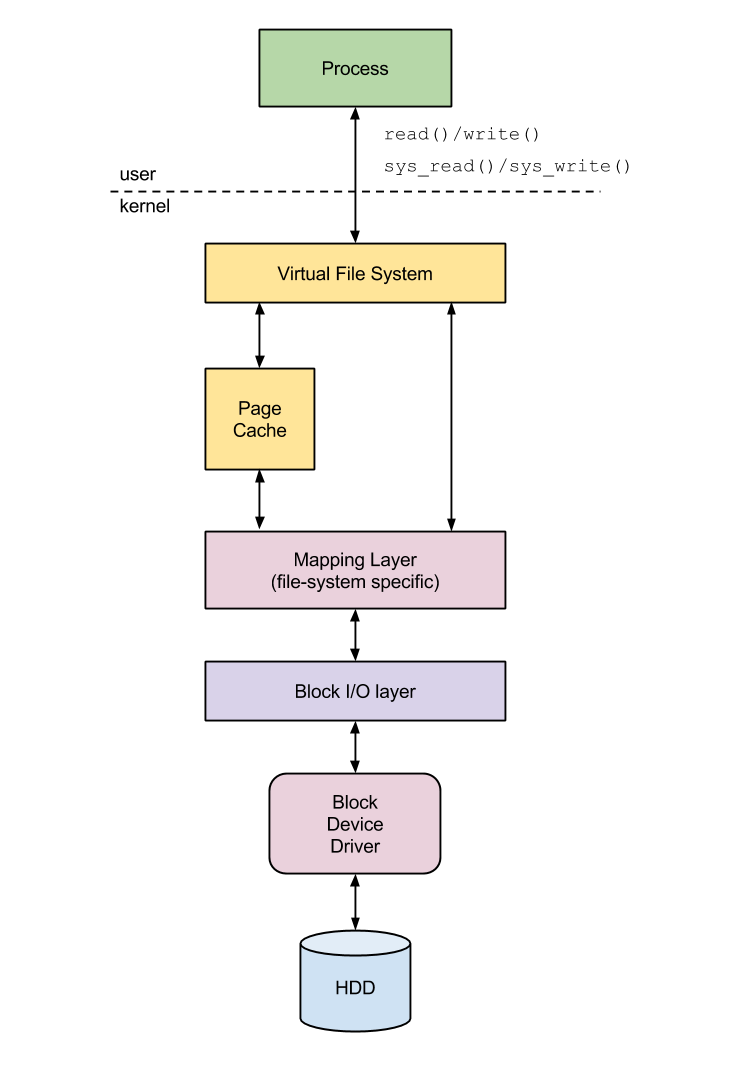
A process accesses a disk with a read() or write() operation of a certain number of bytes. The sys_read() and sys_write() system calls, invoked on behalf of the library, first activate the Virtual File System, that handles two different aspects. When opening, closing or linking a file, it locates the disk and the file system hosting the data, starting from a relative or absolute path. When reading from or writing to an already-open file, it verifies if the data is already mapped into memory (that is, resides in the kernel's page cache) and, if it isn't, it determines how the data can be read from disk. When the VFS finds out that the data is not already mapped into memory, it activates the the kernel susbystem in charge of physically locating the data. The mapping layer initially finds out the size of the file system block corresponding to the data, then it computes the size of the data in terms of number of disk blocks to be transferred. In this phase, the kernel also locates the block numbers that keep the data. As a file can be kept in blocks that are physically not contiguous, the file system keeps track of the mapping between logical blocks and physical blocks. The mapping layer must therefore invoke a mapping function that accesses the file descriptor and pieces together the logical-to-physical mapping, therefore getting, at the end, the position of the actual disk blocks (from the beginning of the disk or of a partition of the disk's file system) keeping the file.
As soon as the positions of the blocks to be mapped into memory are available, the kernel starts to build the I/O requests to forward to the disk device. The block I/O layer creates a list of block I/O structures (called bio), each representing an I/O operation to be submitted to disk. Such structures hide to the upper levels of the hierarchy the specific features of the block device, providing them with an an abstract view of the devices. In the simplest case of small I/O operations one single bio is created, while in more complex cases (large-sized I/Os, vector I/O) the block layer can initiate more I/O operations at a time. Subsequently, the block layer translates I/O operations to requests made for specific sectors, to be sent to the disk controller itself; each request normally contains one or more bios (Figure 2): this helps reducing per-strucure processing overheads. Each of these requests is represented by a request structure; their dispatch to the device driver can be controlled by service policies, implemented in the I/O scheduling sub-component of the block layer.
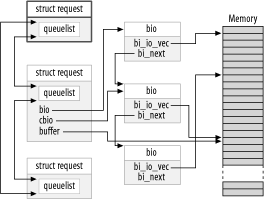
At last, the block layer dispatches the I/O requests to the device driver, which handles the actual data transfer. The device driver is typically provided with a list of available requests, or provides itself a callback to insert a request in some shared data structures. The device driver issues the interface-specific commands as soon as an interrupt is issued from the disk, or a request service is requested from the upper layers of the hierarchy. This interaction between block layer and device driver highly depends on the block layer API which is being used, and will be discussed in much more detail in the next posts of the blog series.
I/O handling techniques
The question arises quite naturally here: are requests simply forwarded by the block layer to the block device driver? Well, actually, no. If they were, the existence of the block I/O layer itself would be pointless. The block layer implements, instead, a number of I/O handling techniques, some of them very simple, some very complex, with a common aim: increasing performance. Some of the implemented techniques, such as I/O scheduling, are typical of a subset of the APIs currently offered by the block layer, and won't be explained here. There are however some that are common to all available interfaces, as they provide relevant benefit regardless of the used API.
Merge and coalesce I/O operations
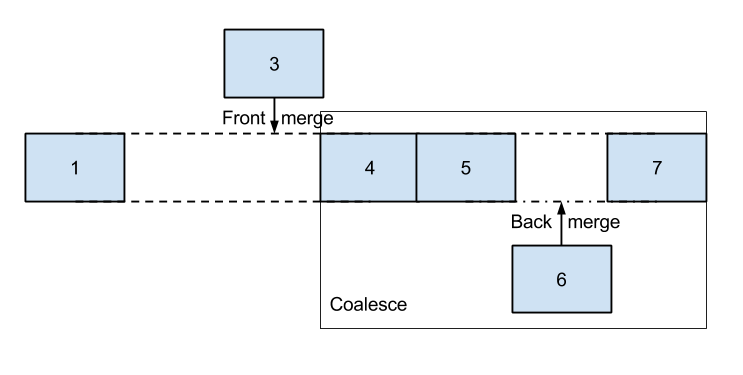
The first operation the block I/O layer performs on a block I/O operation is attempting to merge it to already-inserted structures. This is achieved by searching in the block layer's internal data structures some adjacent requests; if at least one adjoining request is found, the newly-issued block I/O is unified to the existing one. When the existing operation is merged to the new one (because the new one was issued for sectors that preceded the existing one's), the merge is called front merge; else, if the new operation is merged to the existing one (because it was issued for sectors that followed the existing one's) the merge is called back merge. The most common of the two is the latter, as it most likely happens that I/O is performed in a sequential fashion. When, instead, a new operation "fills a gap" between two already-existing structures, the block layer performs a coalesce of the three operations.
Plugging
The block I/O layer includes a mechanism, called plugging, that adjusts the rate at which requests are dispatched to the device driver. If requests are queued to a block device which the block layer does not regard as under load or under stress (that is, with a low number of pending requests), the dispatch of newly-issued operations to the driver is delayed (and the device is said to be plugged). This allows to the block layer to perform a higher number of merges, if more I/O is issued closely (with regard to time and space). After a certain amount of time, or when the number of outstanding I/O for a device exceeds a fixed threshold, the device is unplugged, and the requests are actually dispatched to the device driver.
Initially, plugging was performed system-wide; the idea proved to be effective, but not as effective as it would be if plugging was performed per-device, which would help relieve lock contention on the increasing number of SMP machines. Starting from 2.6.39, plugging was moved to be per-device. Lock contention was still an issue, especially in the case of many processes issuing a high number of small requests to the same block device and constantly hitting on the block layer's per-device data structures each time a merge of a block I/O operation was attempted. Starting from 3.0, plugging was therefore moved to be per-process. This allows block I/O operations to be merged and coalesced in a lockless fashion in a high number of cases; the extent of the impact of this design choice on lock contention actually depends on the API being used.
Request sorting
Some types of block devices have a great benefit from the requests being issued as much as possible in a sequential fashion. As can be probably very easily deduced, the ones that benefit the most from it are devices where the access time to data depends on some mechanical movement: rotational hard drives. When accessing a sector, a rotational disk must move the disk plate where the data is kept (rotational latency) for the sector to be accessible to a head, which must position its head on a specific track (disk head seek). If requests are issued in a random manner, the number of seeks needed to retrieve the sectors increases, adding overhead with respect to sequentially-issued operations.
The block layer typically tries to re-order requests as much as possible, so that they are submitted to the device driver and to disk in a sequential fashion. Plugging helps also with this, allowing the block layer to internally re-order requests before they are submitted.
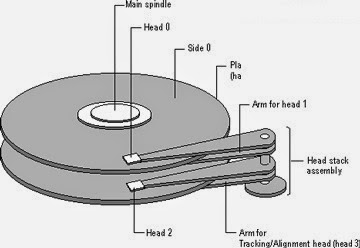
Request sorting is, however, not very useful on some kinds of disks where data transfer time depends (almost) only on the size of the requests, such as solid state drives (SSD). Some solid state disks actually benefit from having many small requests, as they internally serve them in parallel therefore achieving better performance. This technique is therefore left to I/O policies to be used only where it is strictly necessary, and it is even directly skipped in some cases where it does not matter or could introduce overhead which is unnecessary or impacts on performance.
반응형
'【Fundamental Tech】 > Linux' 카테고리의 다른 글
| The block I/O layer, part 3 - The make request interface (0) | 2022.11.19 |
|---|---|
| The block I/O layer, part 2 - The request interface (0) | 2022.11.19 |
| Linux Kernel에서 SSD를 Direct Access하는 방식 (0) | 2022.11.12 |
| Linux Network Stack (0) | 2022.11.05 |
| From rtcwake(util-linux) to Linux Kernel(5.15.71) (0) | 2022.10.25 |



